背景
大学院で研究で、大量のテキストデータが測定結果として出力される実験を行っていました。
1つのファイルには約2000行のデータがあり、1回の測定で1000個近くのファイルが出力されるような状態でした。
これらのデータを手作業で処理しようとした場合、1ファイルあたり1分以上かかるため、1回の測定データを処理するだけで、なんと17時間近くかかってしまいます。
1日に何度も測定することもありましたし、測定後すぐその場で結果を知りたいことも多かったため、手作業での処理は現実的ではありませんでした。
そこで、このテキストデータを処理してすぐにグラフ化できるようなCSVに変換するPythonプログラムを作成しました。
実験の概要
集積回路チップに放射線を照射し、チップに搭載されているリングオシレータ(以下ROと呼ぶ)という発振器の発振周波数(1秒間に発振する回数)を一定時間ごとに測定し、変化を調べる、という実験でした。
RO が搭載された集積回路チップをFPGAと呼ばれるデバイスで操作し、一定時間ごとに発振動作を行わせ、その発振回数をカウントしてマイコンにデータを送ります。マイコンは受け取った発振回数のデータをテキストデータに変換し、PCに送る、という流れです。
テキストデータの内容
チップには回路構成が異なる5種類のROがそれぞれ約400個ずつ、合計約2000個搭載されています。
1つのデータファイル (1回の測定分) には、約2000個のROの発振周波数が順番に1行ずつ書き込まれています。

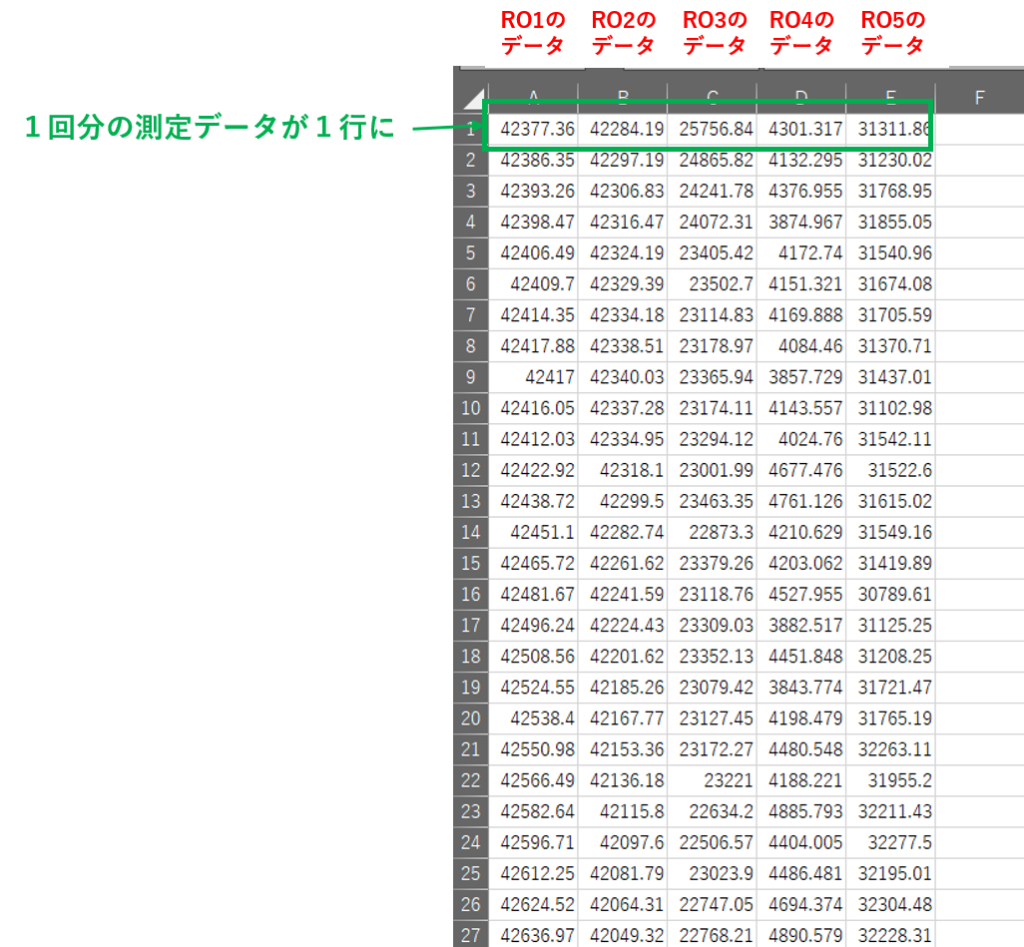
各ROをRO1~RO5と名付けると、各行のデータは以下の表のようになっています。
| 1~390行目 | RO1のデータ |
| 391~810行目 | RO2のデータ |
| 811~1230行目 | RO3のデータ |
| 1231~1650行目 | RO4のデータ |
| 1651~2070行目 | RO5のデータ |
作りたいCSVデータ
目的は、ROの種類別に発振周波数の変化をグラフにすることです。
同じ種類のROが約400個あるので、その平均値をグラフ化するデータとして使用します。
すべてのファイル対して、ROの種類ごとに発振周波数の平均値を求め、縦に並べたCSVデータをつくることができればOKです。
作成したコード
以下が作成したPythonのコードです。
Python 3.8.5で動作を確認しています。
(GitHubのリポジトリはこちら)
#テキストデータを取り込み、各ROごとに平均値を出してファイル順に並べたCSVを生成するプログラム
import csv
import glob
import os
import re
#rawdataフォルダ内のデータのファイルパスをすべて取り込む
filesname = glob.glob("rawdata/*")
#既に処理済みデータがある場合は上書き
if os.path.exists('processed_data.csv'):
os.remove('processed_data.csv')
#1ファイルごとに各ROの平均値を求めて出力ファイルに書き込む
for file in filesname:
lines = [line.rstrip() for line in open(file)]
ro_frequencies=[[],[],[],[],[]]
all_ro = []
for i in range(1650,2070):
ro_frequencies[0].append(int(lines[i]))
for i in range(1230,1650):
ro_frequencies[1].append(int(lines[i]))
for i in range(810,1230):
ro_frequencies[2].append(int(lines[i]))
for i in range(390,810):
ro_frequencies[3].append(int(lines[i]))
for i in range(0,390):
ro_frequencies[4].append(int(lines[i]))
for ro_frequency in ro_frequencies:
average = sum(ro_frequency)/len(ro_frequency)
all_ro.append(average)
with open('processed_data.csv','a',newline='') as f:
writer = csv.writer(f)
writer.writerow(all_ro)補足
- importしているモジュールやライブラリは全て標準のものです。
- テキストファイルの名前は
測定開始からの経過秒.txtという形式ですが、勝手に数字が小さい順に並んでくれているので、とくに並べ替えの処理はしていません。 - 配列
ro_frequencyに各ROのデータを代入する部分は、txtファイルの行数を直書きしていて、かつ同じような処理を何度も書いていてあまり綺麗ではありませんが、for文でまとめようとするとかえって実行速度が落ちてしまったため、上記のように書いています。
実際の動作
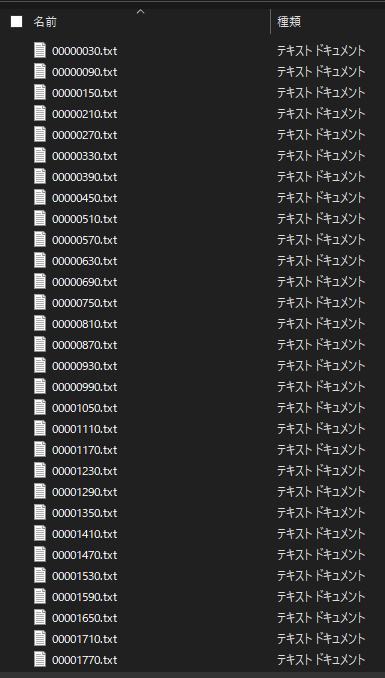
このように生データの.txtファイルが入ったフォルダを rawdataと名付けます。
今回の場合はファイル数が977個でした。
rawdataフォルダと同じ階層にpythonデータを置きます。

この状態でPowershellで以下のようにPythonプログラムを実行します。

約2秒で実行が完了しました。
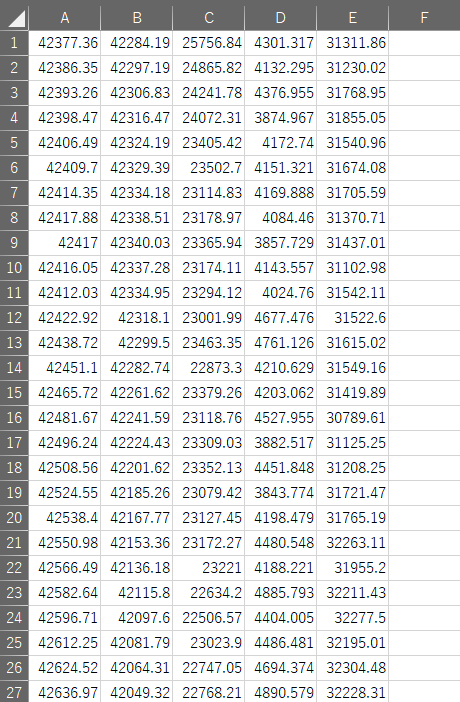
すると、同じ階層にprocessed_data.csvというデータができています。
中身をみると、意図した通りの形式のデータになっています。
コメント
コード自体はかなりシンプルで、特別難しいものではないかと思います。
しかし、このような単純な繰り返し操作で、かつデータの量が多い場合は、プログラミングのコストパフォーマンスが絶大です。
このツールを作ったおかげで少なくとも100時間以上は節約できています。
ゼロからプログラミングを勉強したとしてもお釣りがきますね!
コメント